
The generative AI landscape has evolved considerably over the years, with all of the major platforms out there incorporating new things into the mix.
ChatGPT, the product of OpenAI, has been upgraded to include a wide range of plug ins that might end up making it somewhat more effective than might have been the case otherwise. Over in Google’s corner of the world, the tech juggernaut received the Gemini upgrade which possesses multimodal reasoning capabilities. As if that wasn’t enough, Anthropic has also thrown its hat into the ring with Claude, a new generative AI that possesses a great deal of potential.
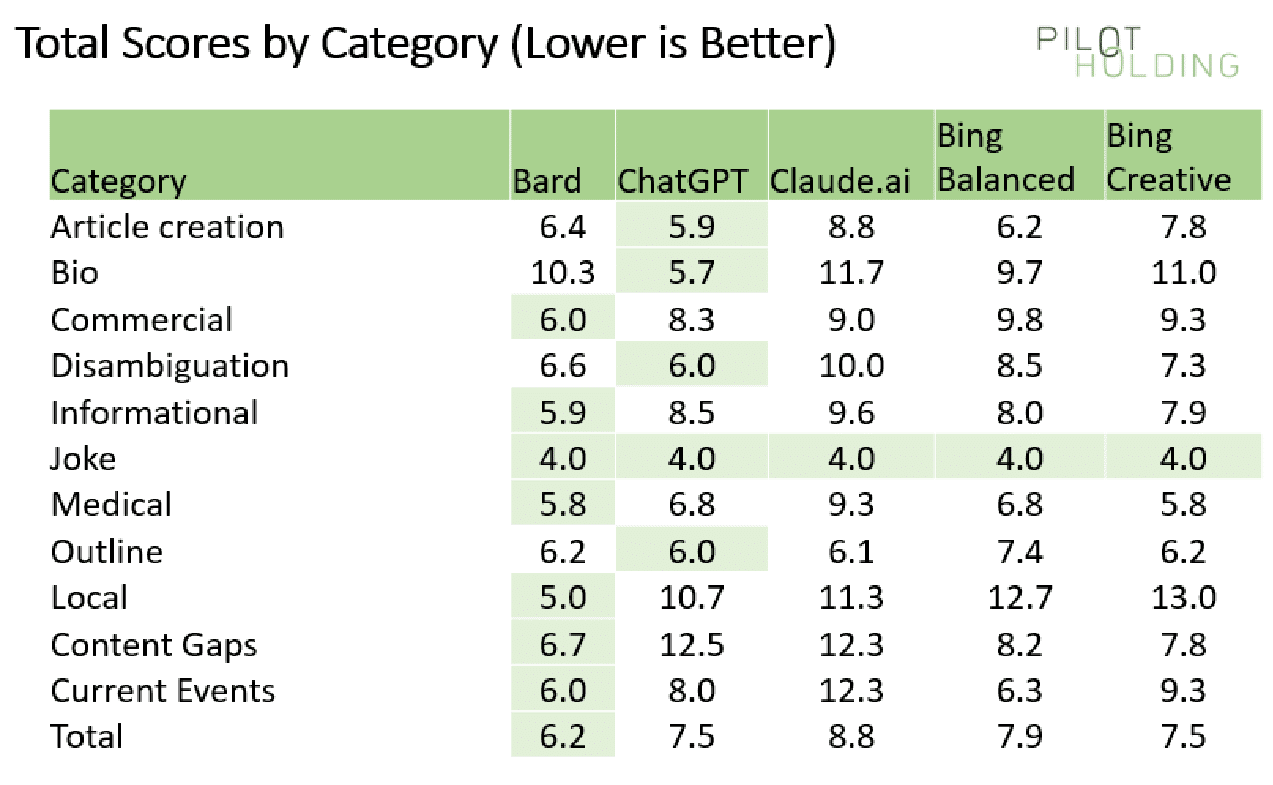
With all of that having been said and now out of the way, it is important to note that Eric Enge of PilotHolding has just conducted a repeat of the same study it conducted 10 months ago (published on SearchEngineLand) for the purposes of ascertaining which of these gen AI work the best. Bard, ChatpGPT, Bing Chat Balanced, Bing Chat Creative and Bard have all been tested out in order to see which of them came out on top.
It turns out that Bard got the best scores based on 44 queries that were put in as part of this test. It even received a perfect score of 4 out of 4 for 2 of these queries, likely due to the reason that they were local search queries with all things having been considered and taken into account.

In spite of the fact that this is the case, Bing Chat was useful in an entirely different way. It provided citations that could be used to determine the origin of any and all information it was provided. Such a feature can be enormously useful because of the fact that this is the sort of thing that could potentially end up allowing users to provide accurate attribution without fail. As for ChatGPT, it underperformed due to its lack of knowledge regarding current events, its lack of relevance to local searches as well as its inability to access current webpages.
The categories of queries that were tested were as follows:
Article Creation: This judged how ready a generated article would be for publishing.
Bio: These queries were all about obtaining information about an individual, and they were scored based on accuracy.
Commercial: These involved attempting to get data about products, and the quality of the information factored into the score.
Disambiguation: Some bio queries involve two or more people of the same name. The chatbots were scored based on how effectively they could separate the two.
Joke: These were non-serious queries meant to gauge how well the chatbot avoided giving an answer to them.
Medical: While chatbots might be able to provide information about this, they were scored based on whether or not they recommended that the user see a doctor.
Article outlines: In this test, the chatbot was scored based on how much modification was required to an outline it provided which a writer could use to compose an article of their own.
Local: These queries ideally should’ve received a response pointing the inquirer to local stores with desired products. As mentioned above, Bard was the best performing chatbot in this regard.
Content gap analysis: This query was meant to obtain responses that could recommend improvements to the content on any given page.
These categories were scored based on five metrics, namely how on topic they were, their accuracy, the completeness of the answers, their overall quality, and finally, the linking of resources.
Bard scored over 90% for being on topic, although ChatGPT surpassed it somewhat, and Claude was the worst performing chatbot in this regard. Accuracy was one area where ChatGPT seriously lagged behind, and Bard excelled in it. Overall, it seems like Bard is truly becoming the best chatbot out there.
Read next: New Survey of Business Executives by Fortune Shows that Elon Musk is the Most Overrated CEO in America



